
What Character.AI’s Logging System Teaches Us About Observability at Scale

For anyone building large-scale AI services, this case study offers valuable lessons.
1. The Core Problem: Scale and Cost
The article starts with a mind-blowing figure:
“450 PB of uncompressed log text produced per month.”
That’s 450 petabytes of raw logs — per month. On top of that, the logs come from multiple clouds, clusters, and teams, making queries slow and costs unpredictable.
Most companies at this stage would simply delete data. Character.AI took a smarter approach

2. Key Design Choices
From my reading, three ideas stand out:
(1) Sampling and Compression — Balancing Signal and Cost
The article explains:
“Info-level logs are sampled (1/10,000 for backbone services, ~1% for other services), while error and warning logs are retained in full.”
This is a rational tradeoff. Not every info log matters. What matters is capturing error and warning signals in full. Combined with ClickHouse’s columnar storage, they achieved 15–20x compression, dramatically reducing storage pressure.
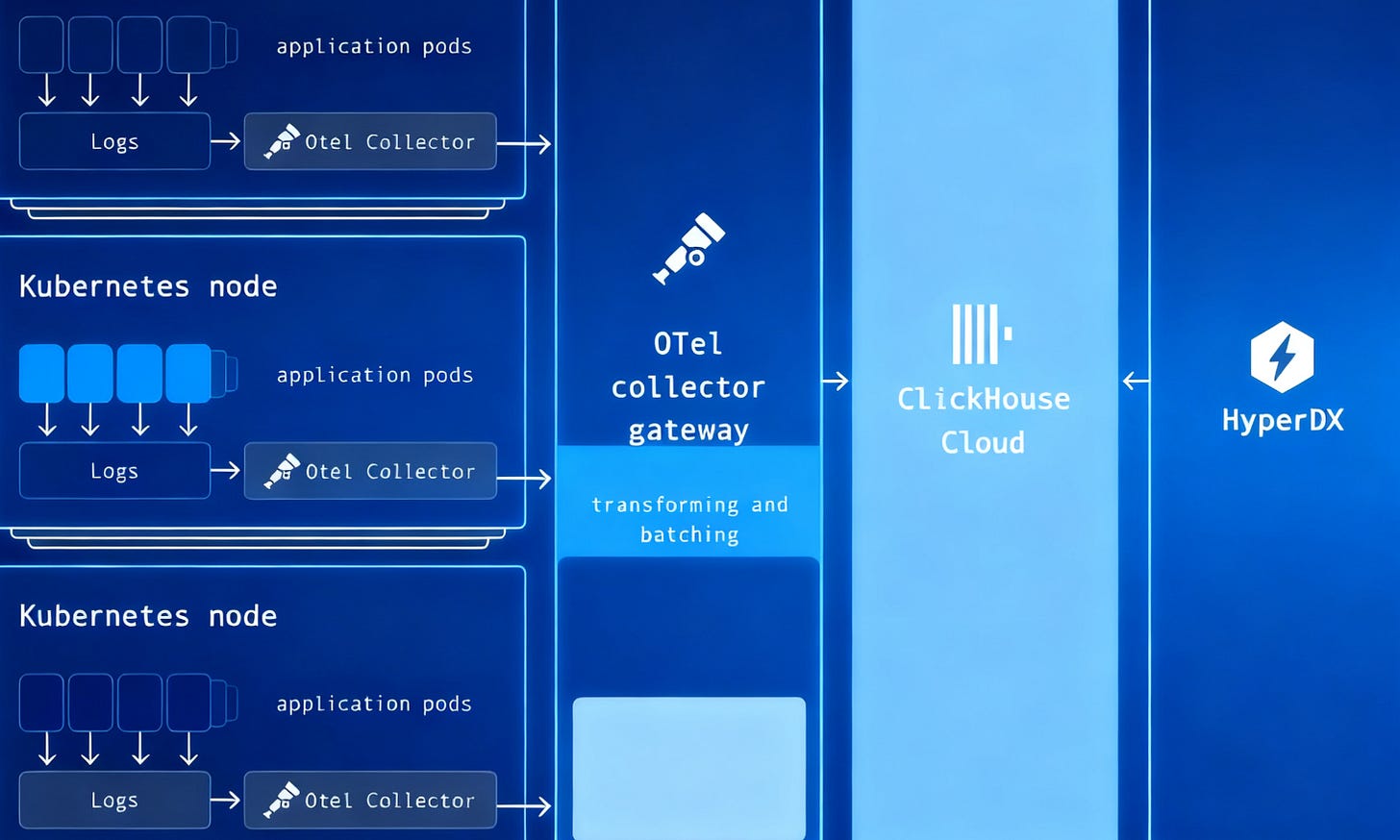
(2) Real-Time Ingestion and Query Optimization — Logs Must Be Usable
They deployed OpenTelemetry Collectors on each node to batch and asynchronously write logs into ClickHouse.
The article also notes:
“Schema and indexing optimizations… removing unused skip indexes and tuning column compression.”
This shows they didn’t just “throw hardware” at the problem. Careful schema design, materialized views, and index tuning make the difference between queries taking seconds vs. minutes.
(3) User Experience — Helping Engineers, Not Just Storing Data
The blog highlights practical features like:
Live tailing (see new logs in real time)
Denoise & Event Patterns (reduce noise, cluster similar logs)
Free-text search (paste any error snippet and search, Lucene-style)
These may look like “UI extras,” but in practice they’re what makes engineers actually want to use the system.
3. The Results: 10x Logs, 50% Lower Cost
What impressed me most was this line:
“Despite a 10x increase in logs, costs dropped by ~50%.”
That proves an important point: good architecture doesn’t just handle growth — it also reduces cloud bills. For any modern SaaS company, that’s a competitive edge.
4. My Takeaways
Here’s what I think we can learn from this case:
Sampling is not “losing data,” it’s smarter data management.
Keeping every info log is wasteful at scale. By retaining all errors/warnings and compressing aggressively, you keep the signal while cutting noise.Observability should be “usable,” not just “stored.”
Too many teams treat logs like backups. Character.AI shows that logs become valuable when queries are instant, searches are free-text, and engineers can explore data intuitively.End-to-end optimization matters.
From ingestion (OpenTelemetry), storage (ClickHouse), schema/index tuning, to exploration (live tailing, pattern detection) — each layer was optimized. This is far more sustainable than relying on an opaque SaaS tool.

5. Closing Thoughts
Character.AI’s story shows that observability is not a “nice-to-have” — it’s a prerequisite for scaling AI infrastructure.
When you’re running thousands of GPUs and millions of concurrent connections, “just add more machines” doesn’t work. You need smarter ways to collect, compress, store, and query logs.
I especially agree with this line from the article:
“Optimizations at small scale have a huge payoff at large scale.”
Lay the foundation early. Otherwise, when your traffic and GPUs grow 10x, you’ll be buried under logs and bills.