
Building Production Data Pipelines: ClickHouse Meets AWS Glue
The modern data stack demands seamless integration between analytical databases and cloud-native ETL services. Today’s announcement of the…

The modern data stack demands seamless integration between analytical databases and cloud-native ETL services. Today’s announcement of the official ClickHouse Connector for AWS Glue represents a significant step forward in simplifying this integration, particularly for organizations running large-scale data processing workloads.
The Integration Challenge
Data engineers often face the complexity of connecting high-performance analytical databases like ClickHouse with managed ETL services. Traditional approaches required manual connector installation, dependency management, and custom configuration scripts. This created friction in the development cycle and made scaling data pipelines more challenging than necessary.
The new ClickHouse AWS Glue connector eliminates these pain points by providing a marketplace-ready solution that integrates directly with AWS’s serverless data integration platform.
Technical Architecture and Capabilities
Core Foundation
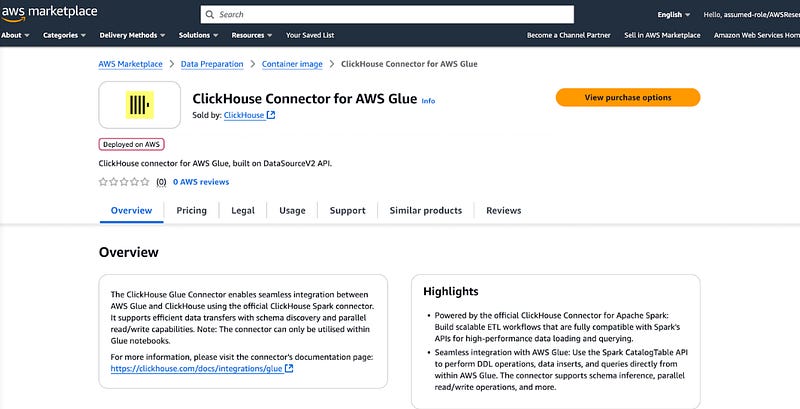
The connector builds upon ClickHouse’s native Spark connector, leveraging AWS Glue’s Apache Spark 3.3 runtime environment. This architecture choice provides several advantages:
Serverless execution: No infrastructure management required
Automatic scaling: Glue handles resource allocation based on workload demands
Native Spark APIs: Full compatibility with existing PySpark and Scala workflows
Enterprise security: Integrated with AWS IAM and VPC networking
Official website blog post
https://clickhouse.com/blog/clickhouse-connector-aws-glue?v=1
Supported Operations
The connector supports comprehensive data operations through familiar Spark APIs:
DDL Management: Execute CREATE, ALTER, and DROP operations using Spark SQL syntax. The connector translates these operations into ClickHouse-specific DDL, handling engine specifications and optimization hints automatically.
Data Ingestion: Utilize Spark’s DataFrameWriteV2 API for efficient bulk loading. The connector optimizes write operations by supporting various serialization formats including Arrow and JSON, with configurable batch sizes for performance tuning.
Data Extraction: Query ClickHouse tables directly through Spark SQL, enabling complex analytical operations that combine data from ClickHouse with other sources in your Glue workflow.
Implementation Deep Dive
Configuration Strategy
The connector’s configuration follows AWS best practices for parameterization and security:
python
# Connection parameters as Glue job arguments
spark.conf.set("spark.sql.catalog.clickhouse", "com.clickhouse.spark.ClickHouseCatalog")
spark.conf.set("spark.sql.catalog.clickhouse.protocol", "https")
spark.conf.set("spark.sql.catalog.clickhouse.host", args["CLICKHOUSE_HOST"])
spark.conf.set("spark.sql.catalog.clickhouse.http_port", args["CLICKHOUSE_PORT"])This approach enables environment-specific configurations while maintaining security through AWS parameter store integration.
Data Processing Patterns
The connector excels in several common data engineering patterns:
Multi-source Aggregation: Combine data from various sources (S3, RDS, other databases) before loading into ClickHouse. This is particularly powerful for creating wide analytical tables from normalized operational data.
Real-time Batch Processing: Process streaming data that’s been staged in S3, apply transformations, and load into ClickHouse for immediate analytical availability.
Data Warehouse Modernization: Migrate legacy ETL processes to a serverless architecture while maintaining compatibility with existing ClickHouse schemas.
Performance Considerations
Optimization Parameters
The connector provides several tuning options for production workloads:
Batch Size Configuration: Adjust the number of records processed in each write operation
Connection Management: Configure timeout settings for reliable network operations
Serialization Format: Choose between Arrow and JSON based on data characteristics
Resource Allocation
AWS Glue’s dynamic resource allocation works particularly well with ClickHouse’s columnar architecture. The connector automatically handles:
Memory Management: Optimizes Spark executor memory for columnar data processing
Parallelization: Distributes write operations across multiple Glue workers
Error Handling: Implements retry logic for network-related failures
Production Deployment Strategies
Workflow Integration
Modern data teams require orchestration capabilities that extend beyond individual job execution. The connector integrates seamlessly with AWS Glue Workflows, enabling:
Scheduled Operations: Configure cron-based triggers for regular data updates Event-Driven Processing: Respond to S3 events or CloudWatch triggers Multi-Job Coordination: Chain multiple Glue jobs with conditional execution logic
Infrastructure as Code
Production deployments benefit from CloudFormation templates that define the entire pipeline infrastructure:
yaml
TriggerSample1CFN:
Type: AWS::Glue::Trigger
Properties:
Type: SCHEDULED
Actions:
- JobName: !Ref ClickHouseETLJob
Schedule: cron(0/10 * ? * MON-FRI *)This approach ensures consistent deployments across environments and simplifies disaster recovery scenarios.
Environment Management
The parameter-driven configuration enables sophisticated environment management:
Development Isolation: Use separate ClickHouse clusters for dev/test/prod
Data Volume Controls: Adjust processing parameters based on environment capacity
Security Boundaries: Apply different IAM roles and VPC configurations per environment
Enterprise Considerations
Security Integration
The connector aligns with enterprise security requirements through:
IAM Integration: Fine-grained permissions for different team members and automated processes VPC Networking: Support for private subnet deployments and security group configurations Credential Management: Integration with AWS Secrets Manager for secure credential handling
Monitoring and Observability
Production deployments require comprehensive monitoring capabilities:
CloudWatch Integration: Automatic logging and metrics collection
Job Performance Tracking: Built-in visibility into execution times and resource utilization
Error Notification: Integration with SNS for alert management
Looking Forward
The connector’s initial release focuses on the most common production use case: batch data loading. However, the roadmap includes several compelling enhancements:
Visual Interface Support: Integration with AWS Glue Studio’s no-code interface will democratize ClickHouse integration for non-technical users.
Advanced Catalog Integration: Automated schema discovery and metadata synchronization will reduce manual configuration overhead.
Enhanced Security Features: Deeper integration with AWS security services will support more complex enterprise requirements.
Strategic Implications
This connector represents more than a technical integration — it signals the maturation of the cloud-native analytical stack. Organizations can now:
Reduce Operational Overhead: Eliminate the need for custom connector maintenance
Accelerate Development Cycles: Focus on business logic rather than infrastructure concerns
Scale Cost-Effectively: Leverage serverless pricing models for variable workloads
Maintain Performance: Achieve production-grade performance without infrastructure complexity
The ClickHouse AWS Glue connector bridges the gap between analytical database performance and cloud-native operational simplicity. For data teams building modern analytical platforms, this integration offers a compelling path forward that balances performance, scalability, and operational efficiency.
Organizations evaluating their data platform strategy should consider how this connector fits into their broader cloud migration and modernization initiatives. The combination of ClickHouse’s analytical performance with AWS Glue’s serverless execution model creates opportunities for more sophisticated, cost-effective data processing architectures.